部署CosyVoice语音合成模型
ubuntu 部署CosyVoice声音克隆模型
TTS (Text To Speech) 文本转语音
部署人工智能开源模型的过程中,一定会遇到各种坑。这个系列我想针对conda做个总结,名字就叫“一定要用conda,不然会出错”。
一、部署方法
git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git
cd CosyVoice
git submodule update --init --recursive
conda create -n cosyvoice python=3.8
conda activate cosyvoice
conda install -y -c conda-forge pynini==2.1.5
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
sudo apt-get install sox libsox-dev
# git模型下载,请确保已安装git lfs
mkdir -p pretrained_models
git clone https://www.modelscope.cn/iic/CosyVoice-300M.git pretrained_models/CosyVoice-300M
git clone https://www.modelscope.cn/iic/CosyVoice-300M-SFT.git pretrained_models/CosyVoice-300M-SFT
git clone https://www.modelscope.cn/iic/CosyVoice-300M-Instruct.git pretrained_models/CosyVoice-300M-Instruct
git clone https://www.modelscope.cn/iic/CosyVoice-ttsfrd.git pretrained_models/CosyVoice-ttsfrd
二、运行方法
conda activate cosyvoice
cd CosyVoice
python3 webui.py --port 50000 --model_dir pretrained_models/CosyVoice-300M
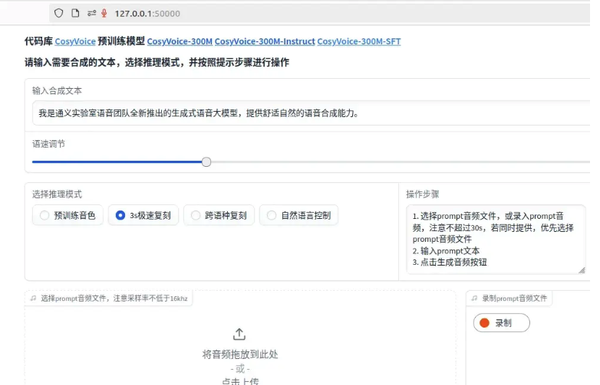
三、运行成功界面
文档信息
版权声明:可自由转载(请注明转载出处)-非商用-非衍生
发表时间:2025年1月3日 17:09